This blog post implements logistic regression with momentum from scratch in Python and performs three experiments evaluating the loss and accuracy.
Author
Emmanuel Towner
Published
April 9, 2025
Implementing Logistic Regression
Abstract
This notebook implements a logistic regression model with a gradient descent optimizer. The model is trained on a synthetic dataset, and in where it is optimized at each iteration and also updates loss. There are four experiments conducted. The first experiment tested the model on with vanilla gradient descent plotting the loss per iteration and a decision boundary. The second experiment compared the loss per iterations between the model when using the vanilla descent and when using momentum descent. The third experiment was to overfit the model to the training data and compare it to the accuracy of the model on the test data. The fourth experiment was to test the model on a heart disease prediction dateset. The dataset was split into training, validation, and test data. The model was trained on the training data and the loss computed for both training and validation. The model was then evaluated on the test data, and the accuracy was reported.
Code
%load_ext autoreload%autoreload 2from logistic import LogisticRegression, GradientDescentOptimizerimport torchimport numpy as npdef classification_data(n_points =300, noise =0.2, p_dims =2): y = torch.arange(n_points) >=int(n_points/2) y =1.0*y X = y[:, None] + torch.normal(0.0, noise, size = (n_points,p_dims)) X = torch.cat((X, torch.ones((X.shape[0], 1))), 1)return X, yX, y = classification_data(noise =0.5)
Code
The previous cell defines a function `classification_data` that generates synthetic classification data using PyTorch. It creates a dataset with a specified number of points, noise level, and feature dimensions. The function returns feature matrix `X` and label vector `y`. The cell then generates a dataset with added noise and stores the results in `X` and `y`.
Experiments
Experiment 1: Vanilla Logistic Regression
In this experiment, I train a logistic regression model using vanilla gradient descent on synthetic data. I monitor the loss over iterations and visualize the decision boundary to evaluate how well the model learns to classify the data.
Code
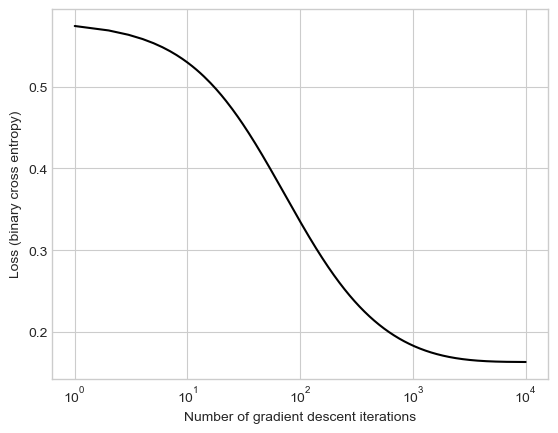
import matplotlib.pyplot as pltLR = LogisticRegression() opt = GradientDescentOptimizer(LR)loss_vec = []for _ inrange(10000): loss = LR.loss(X, y) loss_vec.append(loss) opt.step(X, y, alpha =0.1, beta =0)plt.plot(torch.arange(1, len(loss_vec)+1), loss_vec, color ="black")plt.semilogx()labs = plt.gca().set(xlabel ="Number of gradient descent iterations", ylabel ="Loss (binary cross entropy)")
The code above implements a vanilla gradient descent with logistic regression. It is run through a training loop, while keeping track of the loss and storing it in an array called loss_vec. Using loss_vec, I plot a graph showing the loss over gradient iterations. The second graph shows the decision boundary of the data. - Loss: This appears to hit convergence with a loss <0.2 at ~10,000 iterations. - Decision Boundary: The decision boundary appears to correctly classify the data.
Experiment 2: Benefits of Momentum
Here, I compare vanilla gradient descent with gradient descent using momentum. By plotting the loss over iterations for both methods, I demonstrate how momentum can accelerate convergence when training logistic regression.
Code
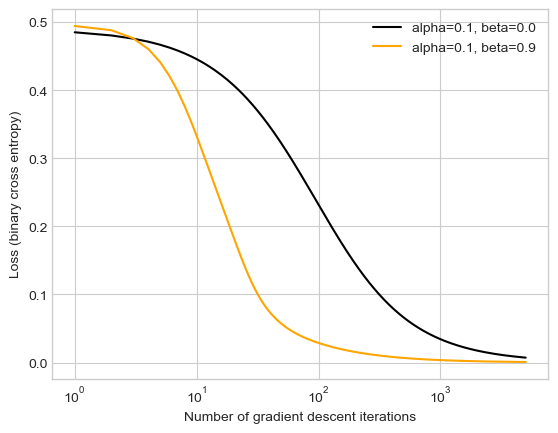
X, y = classification_data(n_points=700, noise =0.1)
The code above plots the loss over iterations for both vanilla gradient descent and momentum gradient descent (beta = 0.9) over 5000 iterations with an alpha of 0.1. The loss of both descents begin at ~0.64, but momentum gradient descent drops lower a lot qucker and reaches convergence at ~1000 iterations. Vanilla gradient descent takes ~5000 iterations to reach convergence.
Experiment 3: Overfitting
This experiment investigates overfitting by training a logistic regression model on high-dimensional data (more features than samples). I compare the model’s accuracy on the training and test sets to highlight the effects of overfitting.
Code
# Generate training and test dataX_train, y_train = classification_data(n_points=60, noise =0.3, p_dims =100)X_test, y_test = classification_data(n_points=60, noise =0.3, p_dims =100)
Code
# Initialize the logistic regression model and optimizerLR = LogisticRegression() opt = GradientDescentOptimizer(LR)# Train the model using momentumfor _ inrange(200): opt.step(X_train, y_train, alpha =0.01, beta =0.9)
Training Accuracy: 100.00%
Testing Accuracy: 93.33%
This experiments creates equal data for train and test set with 60 points, 100 dimensions and a noise of 0.3. The model(alpha = 0.01, beta = 0.9) is trained on the training set for 200 iterations,leading to overfitting and a training accuracy of a 100%. The accuracy of the model on the test set is 96.67%, which is rather good given the model was overfitted.
Experiment 4: Performance on Empirical Data
In this experiment, I apply my logistic regression model to a real-world dataset: the Kaggle heart disease prediction dataset. I preprocess the data, train the model, and evaluate its performance on training, validation, and test sets.
Code
import kagglehubimport pandas as pdfrom sklearn.model_selection import train_test_split# Download dataset from Kagglepath = kagglehub.dataset_download("shantanugarg274/heart-prediction-dataset-quantum")print("Path to dataset files:", path)data_path = path +"/Heart Prediction Quantum Dataset.csv"df = pd.read_csv(data_path)
Warning: Looks like you're using an outdated `kagglehub` version (installed: 0.3.8), please consider upgrading to the latest version (0.3.12).
Path to dataset files: /Users/emmanueltowner/.cache/kagglehub/datasets/shantanugarg274/heart-prediction-dataset-quantum/versions/1
The data was in 1 csv file with 7 columns representing age, gender, blood pressure, cholesterol, heart rate, quantum pattern feature, and heart disease.
The data across features widely varied in range and so I used sci-kit learn’s StandardScaler to standardize the both datasets and then converted them into tensors. The model was trained on the training set and the loss computed for both training and validation.
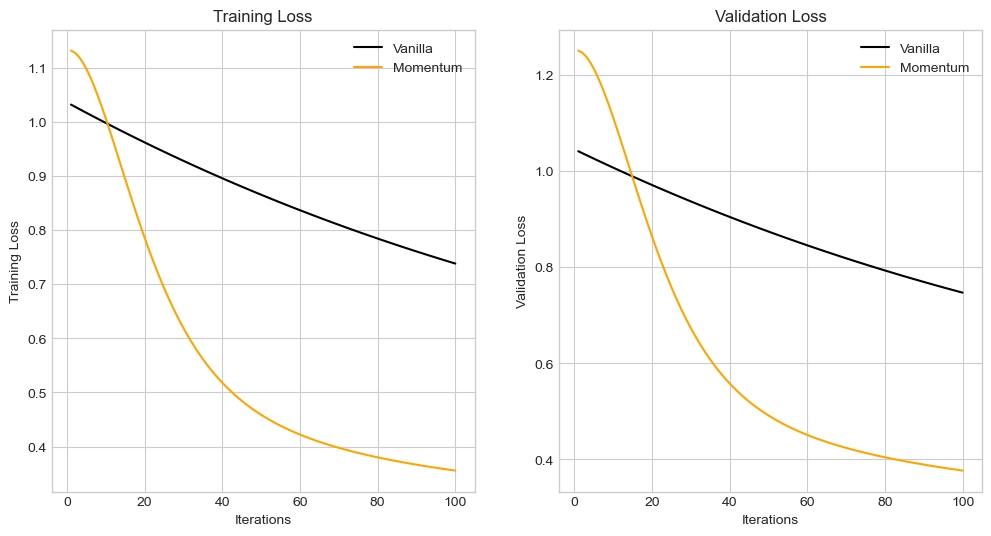
I also used train_test_split to split the 60% data into training, 20% in validation, and test sets. I had to do this in 2 steps since the you cannot split the data into 3 sets at once.
The 2 graphs above show the loss over iterations for both training and validation. The model was trained for 100 iterations with an alpha of 0.01 and mommentum beta of 0.9. The graphs were similar to each other and the only the momentum loss(~0.2 for training and ~0.3 for validation) reached convergence at the end.
My model had a loss of 0.38 and accuracy of 83% on the test set. While the accuracy is was decent, the loss was a bit high.
Discussion
In this blog post, I implemented a logistic regression model with a momentum based optimizer. It successfully achieved convergence with vanilla gradient(beta = 0), then proved the with momentum it could increase speedup. The model was able to overfit the training data and achieve a high accuracy on the test set. The model was also able to learn the heart disease dataset, reach convergence, and achieve a good accuracy. The loss was a bit high, but maybe with more iterations it could be improved.